Java Collection framework
Collection
- 객체의 그룹을 저장하고 조작할 수 있는 아키텍처를 제공하는 프레임워크다.
- 인터페이스와 구현체가 존재하며, 인터페이스를 구현하는 1개 이상의 구현체가 존재한다.
자바답게 인터페이스(List, Queue, Set, Deque)를 제공하고, 이에 대한 구현체 클래스를 제공한다.
단순히 해당 프레임워크의 구현체가 제공하는 메서드에 집중하기 보다는 자바에서 왜 이런 인터페이스 상속 구조를 만들었고, 각 구현체는 어떠한 방법을 사용해서 인터페이스를 구현했는 가에 초점을 맞추는 게 중요할 것으로 보인다.
Hierarchy of Collection Framework
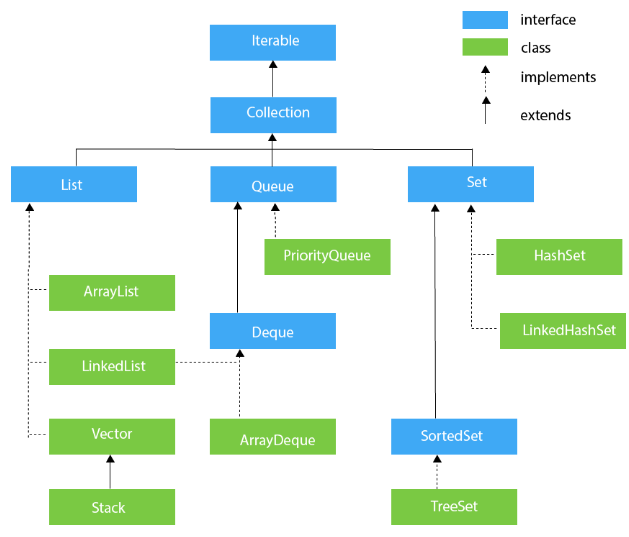
Interface
Iterable interface
이터러블 인터페이스는 자료구조에서 순방향으로 요소를 탐색하는 스펙을 정의한다.
Collection interface
컬렉션 프레임워크는 컬렉션 프레임워크에 해당하는 타입들(List, Queue 등)의 인터페이스가 제공해야하는 공통 메서드 스펙을 정의한다.

즉 이터러블 인터페이스는 요소 순회를, 컬렉션 인터페이스는 컬렉션 프레임워크의 공통 메서드를, 각 하위 서브 클래스들은 자료구조 특성에 따라 필요한 메서드를 추가로 정의한다. 인터페이스 상속을 통한 타입 계층화의 좋은 예시로 보인다.
Implementation example
ArrayList
자바의 배열은 사이즈 제한이 있지만, 어레이 리스트는 동적 배열을 사용하여 언제든지 인자를 추가하거나 제거할 수 있다. 어레이 리스트가 내부적으로 특별한 자료구조를 사용하는 것은 아니고 동일하게 배열을 사용한다. 배열에 데이터를 추가하기 전에 사이즈를 먼저 체크한다. 만약 사이즈 리밋이라면 grow 메서드를 콜하고 아래 과정이 이루어진다.
1. 기존 인자들을 카피한다.
2. 배열 사이즈를 키운다.
3. 새로운 배열을 기존 인자들과 새로운 배열 사이즈로 생성한다.
4. 재참조 시킨다.

사이즈를 체크하고 newCapacity를 계산하고, Arrays의 copyOf 메서드로 기존 인자들, 그리고 사이즈를 새롭게 정의해서 elementData 필드를 재참조 시킨다.
자바 컬렉션 프레임워크에서 사이즈 조절이 동적으로 가능한 자료구조는 아마도 대부분 비슷한 패턴으로 만들어졌을 것이다. 기본적으로 유사한 협력 패턴을 지향하는 언어인 것으로 알고있다.
단 주의할 점은 어레이리스트는 쓰레드 세이프티 하지 않다. 멀티쓰레드 환경에서 공유변수 문제를 피하려면 Vector를 사용하면 된다. (사용하는 메서드 이름은 동일하다. 두 클래스 모두 AbstractList를 상속하기 때문이다.)
LinkedList
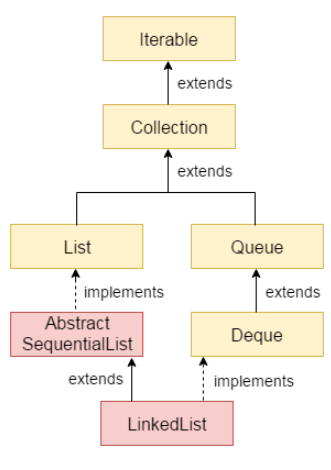
List 인터페이스의 구현체인 LinkedList는 특이하게 Queue, Deque인터페이스도 동시에 구현하고 있다. Doubly LinkedList라서 앞뒤로 인자를 추가하고 제거하는 게 가능하기 때문에 사실상 데크와 동일한 기능을 제공한다. 보통 큐를 사용하는 경우 인덱싱은 거의 사용하지 않고, 앞뒤로 데이터를 추가하고 빼내는게 중요하기 때문에, 같은 인터페이스를 공유하는 ArrayDeque 보다는 LinkedList를 사용하는 것이 더 합리적일 것으로 예상된다.
addFirst, addLast, getFirst, getLast 등의 메서드를 구현하고 있다.
Set
HashSet
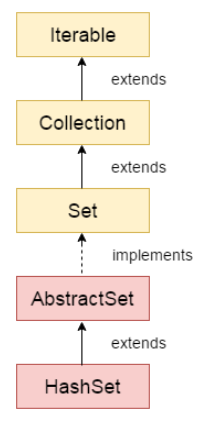
해쉬셋은 해쉬테이블을 스토리지로 사용하는 자료구조다. 리스트는 중복이 허용되지만 해쉬셋은 중복이 허용되지 않는다. 또한 인자의 순서가 보장되지 않는다. 만약 순서까지 보장하고 싶다면 HashSet을 상속한 LinkedHashSet을 사용할 수 있다. 이외에도 TreeSet 등이 순서를 보장해준다. 추가로 EnumSet, EnumMap등은 Enum 클래스를 위한 셋과 맵이다.
Map

맵은 Key-Value 형태로 데이터를 저장할 수 있는 스토리지를 제공하는 자료구조다. Map 인터페이스가 최상위 인터페이스다.
Imlemtation
HashMap
Key-Value 형태로 데이터를 저장한다. LinkedHashMap, TreeMap 등이 추가로 존재하며 순서도 보장해준다.
해쉬맵은 동기화를 제공하지 않는다. 멀티스레드 환경에서는 공유 변수 문제를 피하려면 해쉬테이블을 사용해야한다.
*쓰레드 세이프티 제공 조건을 힙, 스레드 스택 영역의 차이라고 생각했는데, 해당 추측은 틀렸고 메서드 내부에서 동기화 메커니즘을 제공하느냐 안 하느냐의 차이라고 한다.
Hash Collison
자바는 해쉬 충돌을 어떻게 처리할까?
How do HashTables deal with collisions?
I've heard in my degree classes that a HashTable will place a new entry into the 'next available' bucket if the new Key entry collides with another. How would the HashTable still return the correct
stackoverflow.com
자바는 해쉬 충돌 발생 시 내부 구현체에서 Seperate chaning, Open addressing 모두 사용한다고 한다. (Seperate chaning(Use linked list), Open addressing(Move to next available address)
Sorting Collections
자바는 다음과 같은 클래스에 대해 정렬을 실행할 수 있다.
- String objects
- Wrapper class objects
- User-defined class objects
Use case
ArrayList<Integer> arr = new ArrayList<>(Arrays.asList(3, 2, 1);
// Sort by ascending
arr.sort();
// Sort by decending
arr.sort(Collections.reverseOrder());
User definded class
Comparable, Comparator 인터페이스를 상속해서 정렬 기준을 정의할 수 있다.
그렇다면 왜 두 가지 클래스가 존재할까?
Comparable: 단일 인자 정렬, 클래스 내부에 compareTo 정의해서 그대로 사용
Comparator: 다중 인자 정렬, 별도의 클래스로 정의하고 reverseOrder 메서드처럼 인자로 사용.
내림차순 정렬을 할 때 reverseOrder는 Compartor 방식으로 사용했다. 그렇다면 Comparator가 맞을까?

Comparator를 사용하는 것을 확인할 수 있다.
단일, 다중 인자 정렬도 중요하지만 클래스 내부에서 다른 클래스와 비교를 하는 지, 아예 객체 외부에서 비교 로직을 제공하는지의 차이점이 존재한다.
Reference
https://www.javatpoint.com/collections-in-java
Collections in Java - javatpoint
Collections in java or collection framework in java with List, Set, Queue and Map implementation, hierarchy and methods of Java Collections framework, ArrayList, LinkedList, HashSet, LinkedHashSet, TreeSet, HashMap, LinkedHashMap, TreeMap, PriorityQueue, A
www.javatpoint.com